sql中三种去重的方式 sql去除重复数据语句
2021-11-08 15:31:47 爱问问
废话不多说,直接干货。
一、oracle去重
1、创建测试数据
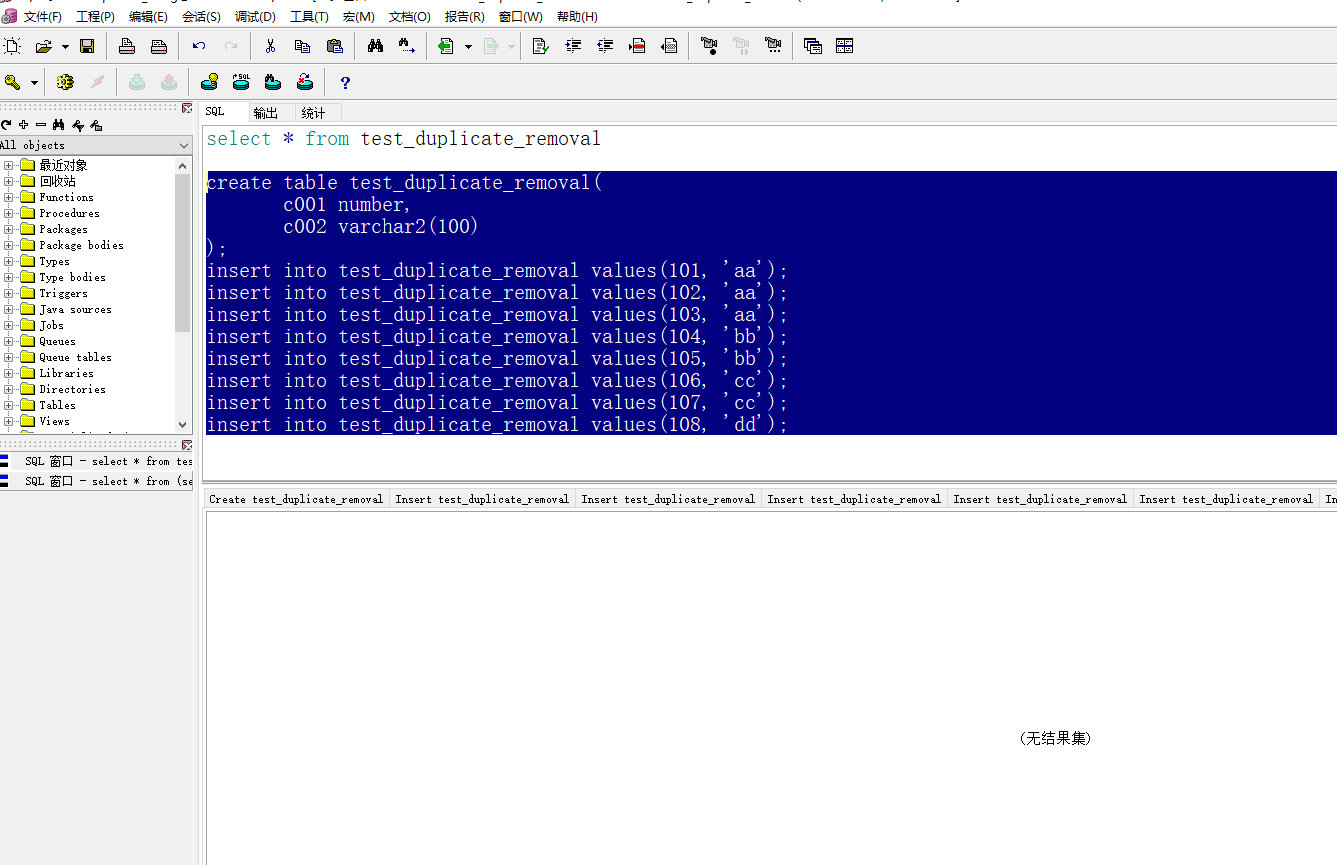
create table test_duplicate_removal(
c001 number,
c002 varchar2(100)
);
insert into test_duplicate_removal values(101, 'aa');
insert into test_duplicate_removal values(102, 'aa');
insert into test_duplicate_removal values(103, 'aa');
insert into test_duplicate_removal values(104, 'bb');
insert into test_duplicate_removal values(105, 'bb');
insert into test_duplicate_removal values(106, 'cc');
insert into test_duplicate_removal values(107, 'cc');
insert into test_duplicate_removal values(108, 'dd');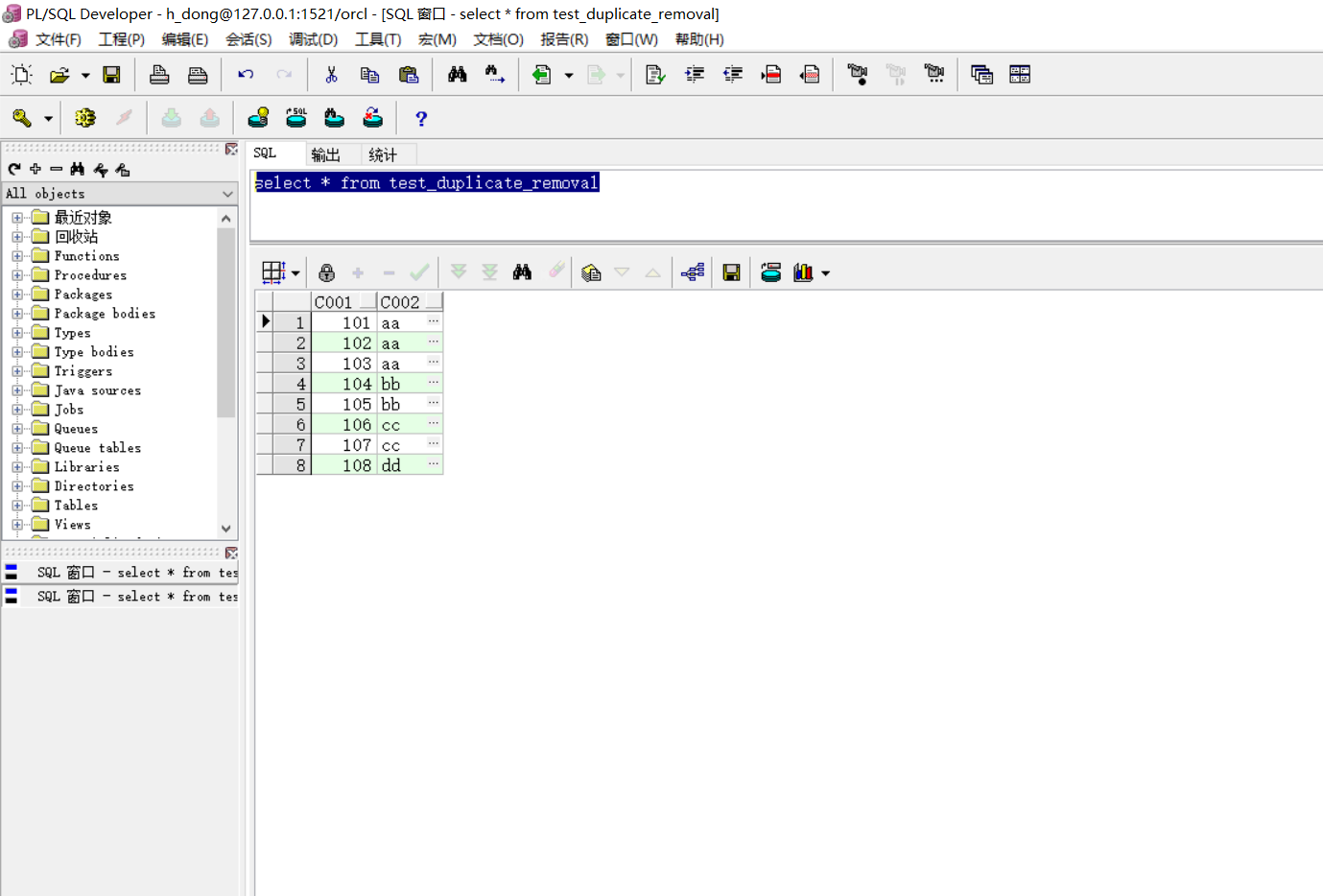
2、使用row_number() over()函数根据C002列去重
创建一个rn列,根据C002进行分组,每个小组内再根据C001的值进行排序。
select c001,c002, row_number() over(partition by c002 order by c001 desc) rn from test_duplicate_removal
通过rn筛选值为1的行,同时也就对C002进行了去重
select * from (select c001,c002, row_number() over(partition by c002 order by c001 desc) rn from test_duplicate_removal) t where t.rn=1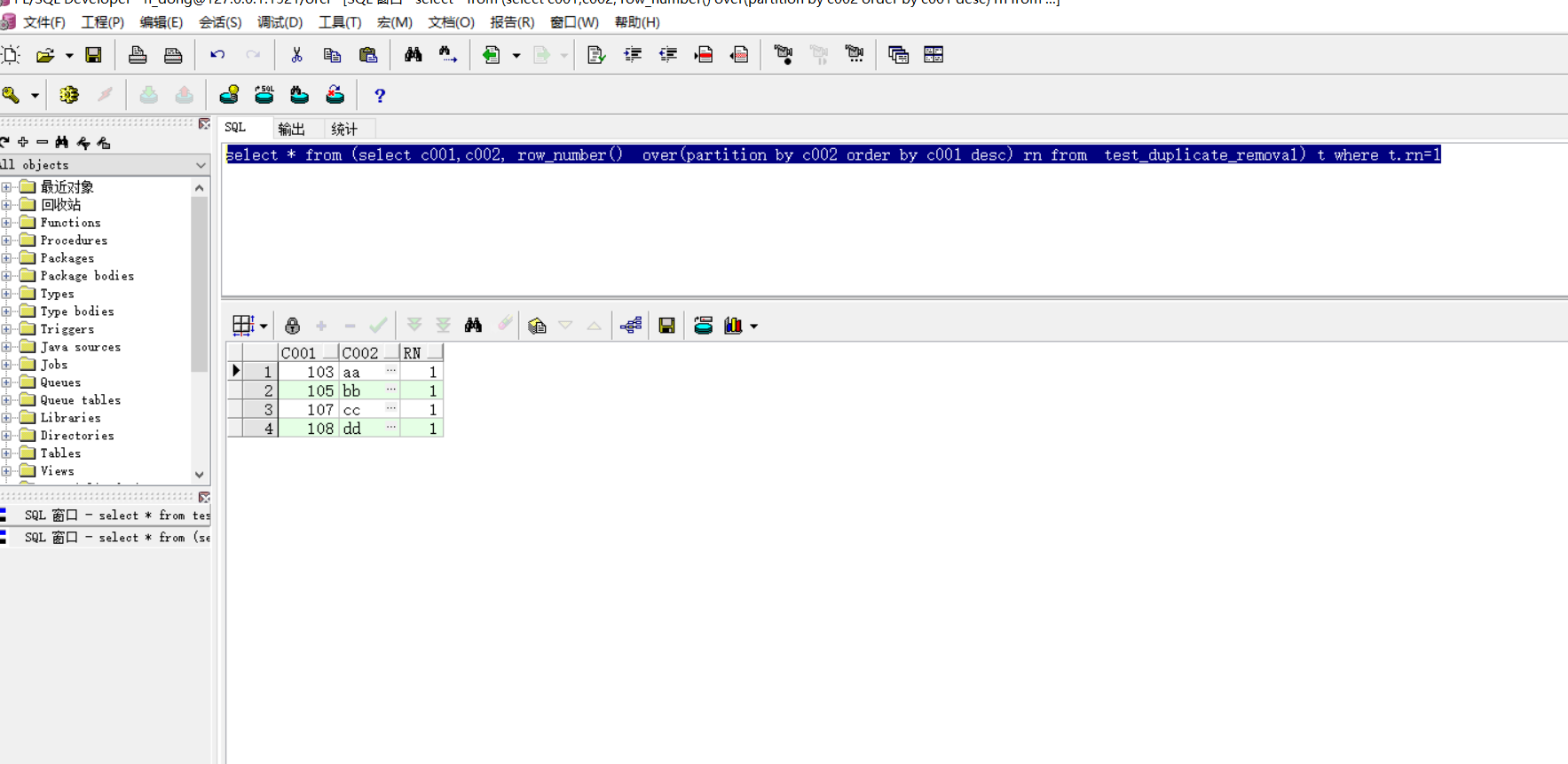
二、python的pandas模块去重方法
1、将数据库数据导出保存为CSV

2、pandas实现sql里排序函数row_number() over()功能
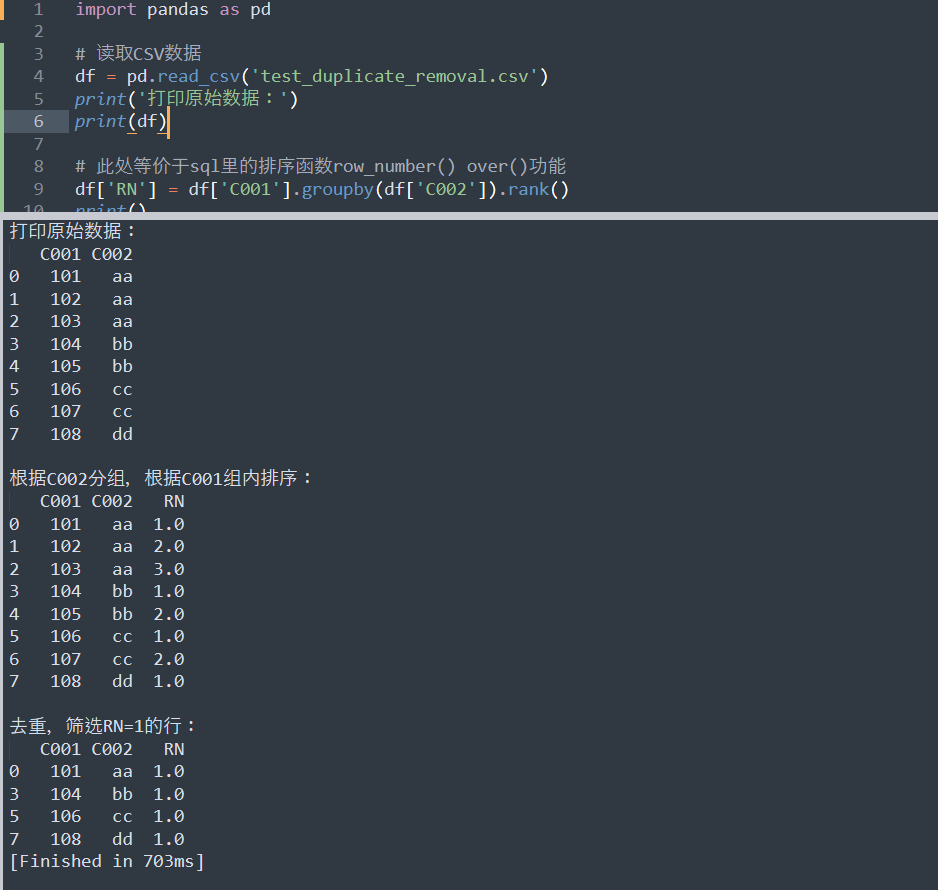
import pandas as pd
# 读取CSV数据
df = pd.read_csv('test_duplicate_removal.csv')
print('打印原始数据:')
print(df)
# 此处等价于sql里的排序函数row_number() over()功能
df['RN'] = df['C001'].groupby(df['C002']).rank()
print()
print('根据C002分组,根据C001组内排序:')
print(df)
# 去重
print()
print('去重,筛选RN=1的行:')
print(df[df['RN'] == 1])运行结果
声明:此文信息来源于网络,登载此文只为提供信息参考,并不用于任何商业目的。如有侵权,请及时联系我们:baisebaisebaise@yeah.net