深度优先策略
2022-06-26 10:04:00 百科资料
深度优先策略,"网络蜘蛛" 学名Spider,又叫"网络爬虫"! 关于网络蜘蛛的概述这里就不多讲了 今天我主要想说的是 关于 蜘蛛的爬行设计的方式与方法。
- 中文名 深度优先策略
- 类型 策略
- 缺点 增加了系统数据的复杂度
- 优点 设计的时候相对比较容易些
简介
"网络蜘蛛" 学名Spider,又叫"网络爬虫"! 关于网络蜘蛛的概述这里就不多讲了 今天我主要想说的是 关于 蜘蛛的爬行设计的方式与方法
详情
我们可以分为2种:
一种是 深度优先策略 一种是 广度优先策略! 以下我们就围绕这2点进行分析 SWJ 非常欢迎大家一起交流 学习与探讨!
深度优先 顾名思义就是 让 网络蜘蛛 尽量的在抓取网页时 往网页更深层次的挖掘进去 讲究的是深度!
也泛指: 网络蜘蛛将会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接!
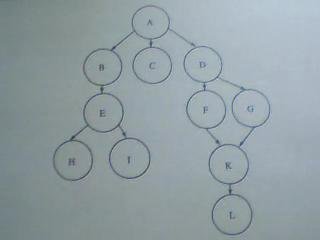
以下我发张图 大家看下: (下面这张是 简单化的网页连接模型图 其中A为起点 也就是蜘蛛索引的起点!)
总共分了5条路径 供蜘蛛爬行! 讲究的是深度!
(下面这张是 经过优化的网页连接模型图! 也就是改进过的蜘蛛深度爬行策略图!)
根据以上2个表格 我们可以得出以下结论:
图1:
路径1 ==> A --> B --> E --> H
路径2 ==> A --> B --> E --> i
路径3 ==> A --> C
路径4 ==> A --> D --> F --> K --> L
路径5 ==> A --> D --> G --> K --> L
经过优化后
图2: (图片已经帮大家标上方向了!)
路径1 ==> A --> B --> E --> H
路径2 ==> i
路径3 ==> C
路径4 ==> D --> F --> K --> L
路径5 ==> G
声明:此文信息来源于网络,登载此文只为提供信息参考,并不用于任何商业目的。如有侵权,请及时联系我们:baisebaisebaise@yeah.net