统计模型[stochasticmodel;statisticmodel;probabilitymodel]指以机率论为基础,採用数学统计方法建立的模型。有些过程无法用理论分析方法导出其模型,但可通过试验测定数据,经过数理统计法求得各变数之间的函式关係,称为统计模型。常用的数理统计分析方法有最大事后机率估算法、最大似然率辨识法等。常用的统计模型有一般线性模型、广义线性模型和混合模型。统计模型的意义在对大量随机事件的规律性做推断时仍然具有统计性,因而称为统计推断。常用的统计模型软体有SPSS、SAS、Stata、SPLM、Epi-Info、Statistica等。
基本介绍
- 中文名:统计模型
- 外文名:statistical model
- 解释:数理统计法求得各变数间函式关係
- 方法分类:最大事后机率估算最大似然率辨识
- 用于:数据分类和综合评价
- 学科:数学
简介
统计模型是一组数学模型,它包含了一组关于样本数据的假设。统计模型通常以相当理想化的形式表示数据生成过程。
统计模型所体现的假设由一组机率分布来描述,其中一些机率分布被假定为充分近似于对特定数据集进行採样的分布。统计模型固有的机率分布是统计模型与其他非统计数学模型的区别。
统计模型通常由与一个或多个随机变数以及可能的其他非随机变数相关的数学方程来指定。因此,统计模型是“理论的形式化表示”。
所有的统计假设检验和所有的统计估计都来自统计模型。更一般地说,统计模型是统计推断基础的一部分。
常用的数理统计分析有最大事后机率估算法,最大似然率辨识法最大事后机率估算法,最大似然率辨识法等。
数据统计模型
多变数统计分析主要用于数据分类和综合评价。综合评价是区划和规划的基础。从人类认识的角度来看有精确的和模糊的两种类型。因为绝大多数地理现象难以用精确的定量关係划分和表示,因此模糊的模型更为实用,结果也往往更接近实际。模糊评价一般经过四个过程:
(1)评价因子的选择与简化;
(2)多因子重要性指标(权重)的确定;
(3)因子内各类别对评价目标的隶属度确定;
(4)选用某种方法进行多因子综合。
1.主成分分析
地理问题往往涉及大量相互关联的自然和社会要素,众多的要素常常给模型的构造带来很大困难。为使用户易于理解和解决现有存储容量不足的问题,有必要减少某些数据而保留最必要的信息。
主成分分析是通过数理统计分析,求得各要素间线性关係的实质上有意义的表达式,将众多要素的信息压缩表达为若干具有代表性的合成变数,这就克服了变数选择时的冗余信息,然后选择信息最丰富的少数因子进行各种聚类分析,构造套用模型。
2.层次分析法(AHP)
Hierarahy Analysis 是T.L.Saaty等在70年代提出和广泛套用的,是系统分析的数学工具之一,它把人的思维过程层次化、数量化,并用数学方法为分析、决策、预报或控制提供定量的依据。
AHP方法把相互关联的要素按隶属关係分为若干层次,请有经验的专家对各层次各因素的相对重要性给出定量指标,利用数学方法综合专家意见给出各层次各要素的相对重要性权值,作为综合分析的基础。例如要比较n个因素y={y1,y2,…,yn }对目标Z的影响,确定它们在z中的比重,每次取两个因素yi和yj,用aij表示yi与yj对Z的影响之比,全部比较结果可用矩阵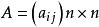 表示,A叫成对比矩阵,它应满足:
表示,A叫成对比矩阵,它应满足:
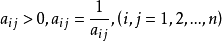
使上式成立的矩阵称互反阵,必有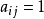 。
。
3.系统聚类分析
60年代末到70年代初,人们把大量精力集中于发展和套用数字分类法,且将这类方法套用于自然资源、土壤剖面、气候分类、环境生态等数据,形成“数字分类学”学科。聚类分析已成为标準的分类技术,在许多大型计算机中都存储了这种分析程式,从GIS资料库中将点数据传送到聚类分析程式也不困难。
聚类分析的主要依据是把相似的样本归为一类,而把差异大的样本区分开来。在由m个变数组成为m维的空间中可以用多种方法定义样本之间的相似性和差异性统计量。
4.判别分析
判别分析是根据表明事物特点的变数值和它们所属的类求出判别函式,根据判别函式对未知所属类别的事物进行分类的一种分析方法,与聚类分析不同,它需要已知一系列反映事物特性的数值变数值及其变数值。
判别分析就是在已知研究对象分为若干类型(组别)并已经取得各种类型的一批已知样品的观测数据基础上,根据某些準则,建立起儘可能把属于不同类型的数据区分开来的判别函式,然后用它们来判别未知类型的样品应该属于哪一类。根据判别的组数,判别分析可以分为两组判别分析和多组判别分析;根据判别函式的形式,判别分析可以分为线性判别和非线性判别;根据判别时处理变数的方法不同,判别分析可以分为逐步判别、序贯判别等;根据判别标準的不同,判别分析有距离判别、Fisher判别、Bayes判别等。
判别分析与聚类分析同属分类问题,所不同的是,判别分析是预先根据理论与实践确定等级序列的因子标準,再将待分析的地理实体安排到序列的合理位置上的方法,对于诸如水土流失评价、土地适宜性评价等有一定理论根据的分类系统定级问题比较适用。
在地理信息系统中发展了一种多因素模糊评价模型,相当于模糊评判分析。该方法首先根据标準类别参数的指标空间确定各因素各类别对目标的隶属度,作为判别距离的度量,再结合要素的权重指数,採用适当的模糊算法,计算各地理实体的归属等级类别,作为评价的基础。该方法通过隶属度表达人们对目标与因素之间关係的模糊性认识,用适当的算法将这种认识量化并反映到结果的分类中,对于地理学中的评价与规划问题非常有效。
地统计模型
地统计(克里金法)模型包括多个组成部分:检查数据(分布、趋势、方向组成和异常值),计算经验半变异函式或协方差值,根据经验值拟合模型,生成克里金方程矩阵以及对其进行求解以为输出表面中的每个位置获取预测值及其关联误差(不确定性)。
计算经验半变异函式
与大多数插值法一样,克里金法基于距离越近的事物就越相似这一基本原则(此处量化为空间自相关)。经验半变异函式是一种发掘这种关係的方法。在距离上彼此接近的点对应比互相远离的点对差异小。在经验半变异函式中可检查使这种假设成立的範围。
拟合模型
拟合通过用点定义可提供最佳拟合的模型来实现。也就是说需要找出一条线,使每个点和这条线之间的加权平方差儘可能小。这称为加权最小二乘拟合。此模型量化数据中的空间自相关。
创建矩阵
克里金方程包含在依赖于测量採样位置和预测位置的空间自相关的矩阵和矢量中。空间自相关值来自于半变异函式模型。矩阵和矢量确定分配给搜寻邻域中的每个测量值的克里金权重。
进行预测
根据测量值的克里金权重,软体对包含未知值的位置计算预测值。
模型的维度
假设我们有一个统计模型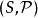 与
与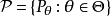 。该模型被认为是参数,如果
。该模型被认为是参数,如果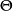 具有有限维度。在记谱中,我们记
具有有限维度。在记谱中,我们记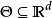 ,其中d是正整数R表示实数。在这里,d被称为模型的维度。
,其中d是正整数R表示实数。在这里,d被称为模型的维度。
如果参数集合统计模型是非参数的 是无限的空间。如果统计模型同时具有有限维和无限维参数,则为半参数。形式上,如果d是维数 和n是样本的数量,都半参数和非参数模型当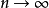 有
有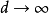 。如果
。如果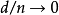 当,那幺模型是半参数的;否则,模型是非参数的。
当,那幺模型是半参数的;否则,模型是非参数的。
参数模型是迄今为止最常用的统计模型。关于半参数模型和非参数模型,戴维·考克斯爵士曾经说过:“这些模型通常包含更少的结构和分布形式的假设,但通常包含对独立性的强烈假设。
目的
统计模型是一类特殊的数学模型。统计模型与其他数学模型的区别在于统计模型是非确定性的。因此,在通过数学方程式指定的统计模型中,一些变数不具有特定的值,而是具有机率分布;即一些变数是随机的。在上面的例子中,ε是一个随机变数;没有这个变数,模型将是确定性的。
即使建模的物理过程是确定性的,也经常使用统计模型。例如,投掷硬币原则上是一个确定性的过程;但它通常被建模为随机的(通过伯努利过程)。
根据Konishi和Kitagawa的观点,统计模型有三个目的:
- 预测
- 信息提取
- 随机结构的描述
")
")


")