
卷积神经网路(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网路(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。卷积神经网路具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网路(Shift-Invariant Artificial Neural Networks, SIANN)”。
对卷积神经网路的研究始于二十世纪80至90年代,时间延迟网路和LeNet-5是最早出现的卷积神经网路;在二十一世纪后,随着深度学习理论的提出和数值计算设备的改进,卷积神经网路得到了快速发展,并被大量套用于计算机视觉、自然语言处理等领域。
卷积神经网路仿造生物的视知觉(visual perception)机制构建,可以进行监督学习和非监督学习,其隐含层内的卷积核参数共享和层间连线的稀疏性使得卷积神经网路能够以较小的计算量对格点化(grid-like topology)特徵,例如像素和音频进行学习、有稳定的效果且对数据没有额外的特徵工程(feature engineering)要求。
基本介绍
- 中文名:卷积神经网路
- 外文名:Convolutional Neural Network, CNN
- 类型:机器学习算法,神经网路算法
- 提出者:Yann LeCun,Wei Zhang,
- :Alexander Waibel 等
- 提出时间:1987-1989年
- 学科:人工智慧
- 套用:计算机视觉,自然语言处理
历史
对卷积神经网路的研究可追溯至日本学者福岛邦彦(Kunihiko Fukushima)提出的neocognitron模型。在其1979和1980年发表的论文中,福岛仿造生物的视觉皮层(visual cortex)设计了以“neocognitron”命名的神经网路。neocognitron是一个具有深度结构的神经网路,并且是最早被提出的深度学习算法之一,其隐含层由S层(Simple-layer)和C层(Complex-layer)交替构成。其中S层单元在感受野(receptive field)内对图像特徵进行提取,C层单元接收和回响不同感受野返回的相同特徵。neocognitron的S层-C层组合能够进行特徵提取和筛选,部分实现了卷积神经网路中卷积层(convolution layer)和池化层(pooling layer)的功能,被认为是启发了卷积神经网路的开创性研究。 neocognition的构筑与特徵可视化
neocognition的构筑与特徵可视化
neocognition的构筑与特徵可视化第一个卷积神经网路是1987年由Alexander Waibel等提出的时间延迟网路(Time Delay Neural Network, TDNN)。TDNN是一个套用于语音识别问题的卷积神经网路,使用FFT预处理的语音信号作为输入,其隐含层由2个一维卷积核组成,以提取频率域上的平移不变特徵。由于在TDNN出现之前,人工智慧领域在反向传播算法(Back-Propagation, BP)的研究中取得了突破性进展,因此TDNN得以使用BP框架内进行学习。在原作者的比较试验中,TDNN的表现超过了同等条件下的隐马尔可夫模型(Hidden Markov Model, HMM),而后者是二十世纪80年代语音识别的主流算法。
1988年,Wei Zhang提出了第一个二维卷积神经网路:平移不变人工神经网路(SIANN),并将其套用于检测医学影像。独立于Zhang (1988),Yann LeCun在1989年同样构建了套用于图像分类的卷积神经网路,即LeNet的最初版本。LeNet包含两个卷积层,2个全连线层,总计6万个学习参数,规模远超TDNN和SIANN,且在结构上与现代的卷积神经网路十分接近。LeCun (1989)对权重进行随机初始化后使用了随机梯度下降(Stochastic Gradient Descent, SGD)进行学习,这一策略被其后的深度学习研究广泛採用。此外,LeCun (1989)在论述其网路结构时首次使用了“卷积”一词,“卷积神经网路”也因此得名。
LeCun (1989)的工作在1993年由贝尔实验室(AT&T Bell Laboratories)完成代码开发并被大量部署于NCR(National Cash Register Coporation)的支票读取系统。但总体而言,由于数值计算能力有限和学习样本不足,这一时期为各类图像处理问题设计的卷积神经网路停留在了研究阶段,没有得到广泛套用。
在LeNet的基础上,1998年Yann LeCun及其合作者构建了更加完备的卷积神经网路LeNet-5并在手写数字的识别问题中取得成功。LeNet-5沿用了LeCun (1989) 的学习策略并在原有设计中加入了池化层对输入特徵进行筛选。LeNet-5及其后产生的变体定义了现代卷积神经网路的基本结构,其构筑中交替出现的卷积层-池化层被认为有效提取了输入图像的平移不变特徵。LeNet-5的成功使卷积神经网路的套用得到关注,微软在2003年使用卷积神经网路开发了光学字元读取(Optical Character Recognition, OCR)系统。其它基于卷积神经网路的套用研究也得到展开,包括人像识别、手势识别等。
2006年后,随着深度学习理论的完善,尤其是逐层学习和参数微调(fine-tuning)技术的出现,卷积神经网路开始快速发展,在结构上不断加深,各类学习和最佳化理论得到引入。自2012年的AlexNet开始,各类卷积神经网路多次成为ImageNet大规模视觉识别竞赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)的优胜算法,包括2013年的ZFNet、2014年的VGGNet、GoogLeNet和2015年的ResNet。
结构
输入层
卷积神经网路的输入层可以处理多维数据,常见地,一维卷积神经网路的输入层接收一维或二维数组,其中一维数组通常为时间或频谱採样;二维数组可能包含多个通道;二维卷积神经网路的输入层接收二维或三维数组;三维卷积神经网路的输入层接收四维数组。由于卷积神经网路在计算机视觉领域有广泛套用,因此许多研究在介绍其结构时预先假设了三维输入数据,即平面上的二维像素点和RGB通道。
与其它神经网路算法类似,由于使用梯度下降进行学习,卷积神经网路的输入特徵需要进行标準化处理。具体地,在将学习数据输入卷积神经网路前,需在通道或时间/频率维对输入数据进行归一化,若输入数据为像素,也可将分布于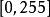 的原始像素值归一化至
的原始像素值归一化至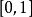 区间。输入特徵的标準化有利于提升算法的运行效率和学习表现。
区间。输入特徵的标準化有利于提升算法的运行效率和学习表现。
隐含层
卷积神经网路的隐含层包含卷积层、池化层和全连线层3类常见构筑,在一些更为现代的算法中可能有Inception模组、残差块(residual block)等複杂构筑。在常见构筑中,卷积层和池化层为卷积神经网路特有。卷积层中的卷积核包含权重係数,而池化层不包含权重係数,因此在文献中,池化层可能不被认为是独立的层。以LeNet-5为例,3类常见构筑在隐含层中的顺序通常为:输入-卷积层-池化层-卷积层-池化层-全连线层-输出。
卷积层(convolutional layer)
1. 卷积核(convolutional kernel)
卷积层的功能是对输入数据进行特徵提取,其内部包含多个卷积核,组成卷积核的每个元素都对应一个权重係数和一个偏差量(bias vector),类似于一个前馈神经网路的神经元(neuron)。卷积层内每个神经元都与前一层中位置接近的区域的多个神经元相连,区域的大小取决于卷积核的大小,在文献中被称为“感受野(receptive field)”,其含义可类比视觉皮层细胞的感受野。卷积核在工作时,会有规律地扫过输入特徵,在感受野内对输入特徵做矩阵元素乘法求和併叠加偏差量:
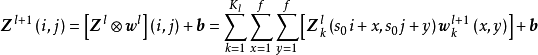
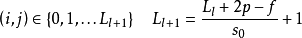
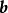
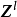
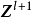
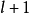
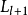
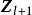
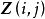
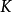
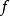
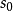
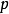
 一维和二维卷积运算示例
一维和二维卷积运算示例上式以二维卷积核作为例子,一维或三维卷积核的工作方式与之类似。理论上卷积核也可以先翻转180度,再求解交叉相关,其结果等价于满足交换律的线性卷积(linear convolution),但这样做在增加求解步骤的同时并不能为求解参数取得便利,因此线性卷积核使用交叉相关代替了卷积。
特殊地,当卷积核是大小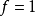 ,步长
,步长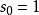 且不包含填充的单位卷积核时,卷积层内的交叉相关计算等价于矩阵乘法,并由此在卷积层间构建了全连线网路:
且不包含填充的单位卷积核时,卷积层内的交叉相关计算等价于矩阵乘法,并由此在卷积层间构建了全连线网路:
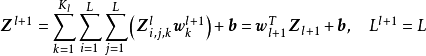
由单位卷积核组成的卷积层也被称为网中网(Network-In-Network, NIN)或多层感知器卷积层(multilayer perceptron convolution layer, mlpconv)。单位卷积核可以在保持特徵图尺寸的同时减少图的通道数从而降低卷积层的计算量。完全由单位卷积核构建的卷积神经网路是一个包含参数共享的多层感知器(Muti-Layer Perceptron, MLP)。
线上性卷积的基础上,一些卷积神经网路使用了更为複杂的卷积,包括平铺卷积(tiled convolution)、反卷积(deconvolution)和扩张卷积(dilated convolution)。平铺卷积的卷积核只扫过特徵图的一部份,剩余部分由同层的其它卷积核处理,因此卷积层间的参数仅被部分共享,有利于神经网路捕捉输入图像的旋转不变(shift-invariant)特徵。反卷积或转置卷积(transposed convolution)将单个的输入激励与多个输出激励相连线,对输入图像进行放大。由反卷积和向上池化层(up-pooling layer)构成的卷积神经网路在图像语义分割(semantic segmentation)领域有重要套用,也被用于构建卷积自编码器(Convolutional AutoEncoder, CAE)。扩张卷积线上性卷积的基础上引入扩张率以提高卷积核的感受野,从而获得特徵图的更多信息,在面向序列数据使用时有利于捕捉学习目标的长距离依赖(long-range dependency)。使用扩张卷积的卷积神经网路主要被用于自然语言处理(Natrual Language Processing, NLP)领域,例如机器翻译、语音识别等。
2. 卷积层参数
卷积层参数包括卷积核大小、步长和填充,三者共同决定了卷积层输出特徵图的尺寸,是卷积神经网路的超参数。其中卷积核大小可以指定为小于输入图像尺寸的任意值,卷积核越大,可提取的输入特徵越複杂。 卷积核中RGB图像的按0填充
卷积核中RGB图像的按0填充
卷积核中RGB图像的按0填充卷积步长定义了卷积核相邻两次扫过特徵图时位置的距离,卷积步长为1时,卷积核会逐个扫过特徵图的元素,步长为n时会在下一次扫描跳过n-1个像素。
由卷积核的交叉相关计算可知,随着卷积层的堆叠,特徵图的尺寸会逐步减小,例如16×16的输入图像在经过单位步长、无填充的5×5的卷积核后,会输出12×12的特徵图。为此,填充是在特徵图通过卷积核之前人为增大其尺寸以抵消计算中尺寸收缩影响的方法。常见的填充方法为按0填充和重複边界值填充(replication padding)。填充依据其层数和目的可分为四类:
- 有效填充(valid padding):即完全不使用填充,卷积核只允许访问特徵图中包含完整感受野的位置。输出的所有像素都是输入中相同数量像素的函式。使用有效填充的卷积被称为“窄卷积(narrow convolution)”,窄卷积输出的特徵图尺寸为(L-f)/s+1。
- 相同填充/半填充(same/half padding):只进行足够的填充来保持输出和输入的特徵图尺寸相同。相同填充下特徵图的尺寸不会缩减但输入像素中靠近边界的部分相比于中间部分对于特徵图的影响更小,即存在边界像素的欠表达。使用相同填充的卷积被称为“等长卷积(equal-width convolution)”。
- 全填充(full padding):进行足够多的填充使得每个像素在每个方向上被访问的次数相同。步长为1时,全填充输出的特徵图尺寸为L+f-1,大于输入值。使用全填充的卷积被称为“宽卷积(wide convolution)”
- 任意填充(arbitrary padding):介于有效填充和全填充之间,人为设定的填充,较少使用。
带入先前的例子,若16×16的输入图像在经过单位步长的5×5的卷积核之前先进行相同填充,则会在水平和垂直方向填充两层,即两侧各增加2个像素(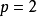 )变为20×20大小的图像,通过卷积核后,输出的特徵图尺寸为16×16,保持了原本的尺寸。
)变为20×20大小的图像,通过卷积核后,输出的特徵图尺寸为16×16,保持了原本的尺寸。
3. 激励函式(activation function)
卷积层中包含激励函式以协助表达複杂特徵,其表示形式如下:
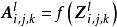
激励函式操作通常在卷积核之后,一些使用预激活(preactivation)技术的算法将激励函式置于卷积核之前。在一些早期的卷积神经网路研究,例如LeNet-5中,激励函式在池化层之后。
池化层(pooling layer)
在卷积层进行特徵提取后,输出的特徵图会被传递至池化层进行特徵选择和信息过滤。池化层包含预设定的池化函式,其功能是将特徵图中单个点的结果替换为其相邻区域的特徵图统计量。池化层选取池化区域与卷积核扫描特徵图步骤相同,由池化大小、步长和填充控制。
1. Lp池化(Lp pooling)
Lp池化是一类受视觉皮层内阶层结构启发而建立的池化模型,其一般表示形式为:
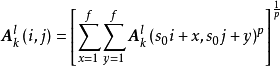
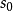
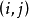
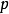
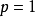
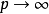
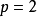
2. 随机/混合池化
混合池化(mixed pooling)和随机池化(stochastic pooling)是Lp池化概念的延伸。随机池化会在其池化区域内按特定的机率分布随机选取一值,以确保部分非极大的激励信号能够进入下一个构筑。混合池化可以表示为均值池化和极大池化的线性组合:
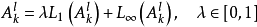
3. 谱池化(spectral pooling)
谱池化是基于FFT的池化方法,可以和FFT卷积一起被用于构建基于FFT的卷积神经网路。在给定特徵图尺寸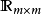 ,和池化层输出尺寸时
,和池化层输出尺寸时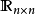 ,谱池化对特徵图的每个通道分别进行DFT变换,并从频谱中心截取n×n大小的序列进行DFT逆变换得到池化结果。谱池化有滤波功能,可以最大限度地保存低频变化信息,并能有效控制特徵图的大小。此外,基于成熟的FFT算法,谱池化能够以很小的计算量完成。
,谱池化对特徵图的每个通道分别进行DFT变换,并从频谱中心截取n×n大小的序列进行DFT逆变换得到池化结果。谱池化有滤波功能,可以最大限度地保存低频变化信息,并能有效控制特徵图的大小。此外,基于成熟的FFT算法,谱池化能够以很小的计算量完成。
Inception模组(Inception module)
Inception模组是对多个卷积层和池化层进行堆叠所得的特殊隐含层构筑。具体而言,一个Inception模组会同时包含多个不同类型的卷积和池化操作,并使用相同填充使上述操作得到相同尺寸的特徵图,随后在数组中将这些特徵图的通道进行叠加并通过激励函式。由于上述做法在一个构筑中引入了多个卷积计算,其计算量会显着增大,因此为简化计算量,Inception模组通常设计了瓶颈层,首先使用单位卷积核,即NIN结构减少特徵图的通道数,再进行其它卷积操作。Inception模组最早被套用于GoogLeNet并取得了显着的成功,也启发了Xception算法中的深度可分卷积(depthwise separable convolution)思想。,GoogLeNet使用的版本(b-d)") Inception模组:原始版本(a),GoogLeNet使用的版本(b-d)
Inception模组:原始版本(a),GoogLeNet使用的版本(b-d)
Inception模组:原始版本(a),GoogLeNet使用的版本(b-d)全连线层(fully-connected layer)
卷积神经网路中的全连线层等价于传统前馈神经网路中的隐含层。全连线层通常搭建在卷积神经网路隐含层的最后部分,并只向其它全连线层传递信号。特徵图在全连线层中会失去3维结构,被展开为向量并通过激励函式传递至下一层。
在一些卷积神经网路中,全连线层的功能可部分由全局均值池化(global average pooling)取代,全局均值池化会将特徵图每个通道的所有值取平均,即若有7×7×256的特徵图,全局均值池化将返回一个256的向量,其中每个元素都是7×7,步长为7,无填充的均值池化。
输出层
卷积神经网路中输出层的上游通常是全连线层,因此其结构和工作原理与传统前馈神经网路中的输出层相同。对于图像分类问题,输出层使用逻辑函式或归一化指数函式(softmax function)输出分类标籤。在物体识别(object detection)问题中,输出层可设计为输出物体的中心坐标、大小和分类。在图像语义分割中,输出层直接输出每个像素的分类结果。
理论
学习範式
监督学习(supervised learning)
参见:反向传播算法
卷积神经网路在监督学习中使用BP框架进行学习,其计算流程在LeCun (1989) 中就已经确定,是最早在BP框架进行学习的深度算法之一。卷积神经网路中的BP分为三部分,即全连线层与卷积核的反向传播和池化层的反向通路(backward pass)。全连线层的BP计算与传统的前馈神经网路相同,卷积层的反向传播是一个与前向传播类似的交叉相关计算:
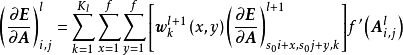
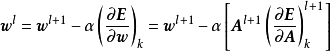
式中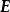 为代价函式(cost function)计算的误差、
为代价函式(cost function)计算的误差、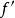 为激励函式的导数、
为激励函式的导数、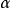 是学习速率(learning rate),若卷积核的前向传播使用卷积计算,则反向传播也对卷积核翻转以进行卷积运算。卷积神经网路的误差函式可以有多种选择,常见的包括Softmax损失函式(softmax loss)、铰链损失函式(hinge loss)、三重损失函式(triplet loss)等。
是学习速率(learning rate),若卷积核的前向传播使用卷积计算,则反向传播也对卷积核翻转以进行卷积运算。卷积神经网路的误差函式可以有多种选择,常见的包括Softmax损失函式(softmax loss)、铰链损失函式(hinge loss)、三重损失函式(triplet loss)等。
池化层在反向传播中没有参数更新,因此只需要根据池化方法将误差分配到特徵图的合适位置即可,对极大池化,所有误差会被赋予到极大值所在位置;对均值池化,误差会平均分配到整个池化区域。
卷积神经网路通常使用BP框架内的随机梯度下降(Stochastic Gradient Descent, SGD)和其变体,例如Adam算法(Adaptive moment estimation)。SGD在每次叠代中随机选择样本计算梯度,在大量学习样本的情形下有利于信息筛选,在叠代初期能快速收敛,且计算複杂度更小。
非监督学习(unsupervised learning)
卷积神经网路在监督学习问题下有广泛套用,但也可以使用无标籤数据进行非监督学习。可用的方法包括卷积自编码器(Convolutional AutoEncoders, CAE)、卷积受限玻尔兹曼机(Convolutional Restricted Boltzmann Machines, CRBM)/卷积深度置信网路(Convolutional Deep Belief Networks, CDBN)和深度卷积生成对抗网路(Deep Convolutional Generative Adversarial Networks, DCGAN)。这些算法也可以视为在非监督学习算法的原始版本中引入卷积神经网路构筑的混合算法。
CAE的构建逻辑与传统AE类似,首先使用卷积层和池化层建立常规的卷积神经网路作为编码器,随后使用反卷积和向上池化(up-pooling)作为解码器,以样本编码前后的误差进行学习,并输出编码器的编码结果实现对样本的维度消减(dimentionality reduction)和聚类(clustering)。在图像识别问题,例如MNIST中,CAE与其编码器同样结构的卷积神经网路在大样本时表现相当,但在小样本问题中具有更好的识别效果。
CRBM是以卷积层作为隐含层的受限玻尔兹曼机(Boltzmann Machines, RBM),在传统RBMs的基础上将隐含层分为多个“组(group)”,每个组包含一个卷积核,卷积核参数由该组对应的所有二元节点共享。CDBN是以CRBM作为构筑进行堆叠得到的阶层式生成模型,为了在结构中提取高阶特徵,CDBN加入了机率极大池化层( probabilistic max-pooling layer),和其对应的能量函式。CRBMs和CDBMs使用逐层贪婪算法(greedy layer-wise training)进行学习,并可以使用稀疏正则化(sparsity regularization)技术。在Caltech-101数据的物体识别问题中,一个24-100的两层CDBN识别準确率持平或超过了很多包含高度特化特徵的分类和聚类算法。
生成对抗网路( Generative Adversarial Networks, GAN)可被用于卷积神经网路的非监督学习,DCGAN从一组机率分布,即潜空间(latent space)中随机採样,并将信号输入一组完全由转置卷积核组成的生成器;生成器生成图像后输入以卷积神经网路构成的判别模型,判别模型判断生成图像是否是真实的学习样本。当生成模型能够使判别模型无法判断其生成图像与学习样本的区别时学习结束。研究表明DCGANs能够在图像处理问题中提取输入图像的重要特徵,在CIFAR-10数据的试验中,对DCGAN判别模型的特徵进行处理后做为其它算法的输入,能以很高的準确率对图像进行分类。
最佳化
正则化(regularization)
参见:正则化
在神经网路算法的各类正则化方法都可以用于卷积神经网路以防止过度拟合,常见的正则化方法包括Lp正则化(Lp-norm regularization)、随机失活(spatial dropout)和随机连线失活(drop connect)。
Lp正则化在定义损失函式时加入隐含层参数以约束神经网路的複杂度:
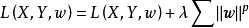
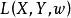
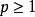
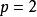
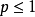
卷积神经网路中的空间随机失活(spatial dropout)是前馈神经网路中随机失活理论的推广。在全连线网路的学习中,随机失活会随机将神经元的输出归零,而空间随机失活在叠代中会随机选取特徵图的通道使其归零。进一步地,随机连线失活直接作用于卷积核,在叠代中使卷积核的部分权重归零。研究表明空间随机失活和随机连线失活提升了卷积神经网路的泛化能力,在学习样本不足时效果显着。
分批归一化(Batch Normalization, BN)
数据的标準化是神经网路输入管道中预处理的重要步骤。在深度网路中,随着特徵在隐含层内的逐级传递,其均值和标準差会随之改变,产生协变漂移(covariate shift)现象。协变漂移是深度网路发生梯度消失(vanishing gradient)的重要原因。BN以引入额外学习参数为代价部分解决了此类问题,其策略是在隐含层中首先将特徵标準化,然后使用两个线性参数将标準化的特徵放大作为新的输入,神经网路会在学习过程中更新其BN参数。卷积神经网路中的BN参数与卷积核参数具有相同的性质,即特徵图中同一个通道的像素共享一组BN参数。此外使用BN时卷积层不需要偏差项,其功能由BN参数代替。
跳跃连线(skip connection) 包含跳跃连线的残差块
包含跳跃连线的残差块
包含跳跃连线的残差块跳跃连线或短路连线(shortcut connection)来源于循环神经网路(Recurrent Neural Network, RNN)中的跳跃连线和各类门控算法,是解决深度网路中梯度消失问题的重要技术。卷积神经网路中的跳跃连线可以跨越任意数量的隐含层,这里以相邻隐含层间的跳跃进行说明:
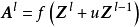

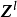
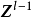
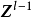
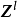
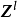
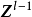
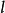
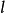
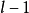
加速
通用加速技术
卷积神经网路可以使用和其它深度学习算法类似的加速技术以提升运行效率,包括量化(quantization)、迁移学习(transfer learning)等。量化即在计算中使用低数值精度以提升计算速度,该技术在各类深度算法中被广泛使用。对于卷积神经网路,一个极端的例子是XNOR-Net,即仅由异或门(XNOR)搭建的卷积神经网路。迁移学习一般性的策略是将非标籤数据迁移至标籤数据以提升神经网路的表现,卷积神经网路中迁移学习通常为使用在标籤数据下完成学习的卷积核权重初始化新的卷积神经网路,对非标籤数据进行迁移,或套用于其它标籤数据以缩短学习过程。
FFT卷积
卷积神经网路的卷积和池化计算都可以通过FFT转换至频率域内进行,此时卷积核权重与BP算法中梯度的FFT能够被重複利用,逆FFT也只需在输出结果时使用,降低了计算複杂度。同时作为被广泛使用的数值计算方法,一些数值计算库包含了GPU设备的FFT,能提供进一步加速。FFT卷积在处理小尺寸的卷积核时可使用Winograd算法降低记忆体开销。
权重稀疏化
在卷积神经网路中对权重进行稀疏化,能够减少卷积核的冗余,降低计算複杂度,使用该技术的构筑被称为稀疏卷积神经网路(Sparse Convolutional Neural Networks)。在对ImageNet数据的学习中,一个以90%比率稀疏化的卷积神经网路的运行速度是同结构传统卷积神经网路的2至10倍,而输出的分类精度仅损失了2%。
算法
一维算法
时间延迟网路(Time Delay Neural Network, TDNN)
TDNN是一类套用于语音识别问题的一维卷积神经网路,也是历史上最早被提出的卷积神经网路算法之一。这里以TDNN的原始版本Waibel et al. (1987)为例进行介绍。 TDNN构筑示意图
TDNN构筑示意图
TDNN构筑示意图TDNN的学习目标为对FFT变换的3个语音音节/b,d,g/进行分类,其隐含层完全由单位步长,无填充的卷积层组成。在文献中,TDNN的卷积核尺寸使用“延迟(delay)”表述,由尺寸为3的一维卷积核构成的隐含层被定义为“时间延迟为2的隐含层”,即感受野包含无延迟输入和2个延迟输入。在此基础上,TDNN有两个卷积层,时间延迟分别为2和4,神经网路中每个输入信号与8个隐含层神经元相连。TDNN没有全连线层,而是将尾端卷积层的输出直接相加通过激励函式得到分类结果。按原作,输入TDNN的预处理数据为15个10毫秒採样的样本(frame),每个样本包含16个通道参数(filterbank coefficients),此时TDNN的结构如下:
- (3)×16×8的卷积层(步长为1,无填充,Sigmoid函式)
- (5)×8×3的卷积层(步长为1,无填充,Sigmoid函式)
- 对9×3的特徵图求和输出
列表中数字的含义为:(卷积核尺寸)×卷积核通道(与输入数据通道数相同)×卷积核个数。TDNN的输出层和两个卷积层均使用Sigmoid函式作为激励函式。除上述原始版本外,TDNN的后续研究中出现了套用于字元识别和物体识别的算法,其工作方式是将空间在通道维度展开并使用时间上的一维卷积核,即时间延迟进行学习。
WaveNet
WaveNet是被用于语音建模的一维卷积神经网路,其特点是採用扩张卷积和跳跃连线提升了神经网路对长距离依赖的学习能力。WaveNet面向序列数据设计,其结构和常见的卷积神经网路有较大差异,这里按Van Den Oord et al. (2016)做简单介绍: WaveNet构筑示意图
WaveNet构筑示意图
WaveNet构筑示意图WaveNet以经过量化和独热编码(one-hot encoding)的音频作为输入特徵,具体为一个包含採样和通道的二维数组。输入特徵在WaveNet中首先进入线性卷积核,得到的特徵图会通过多个扩张卷积块(dilated stack),每个扩张卷积块包含一个过滤器(filter)和一个门(gate),两者都是步长为1,相同填充的线性卷积核,但前者使用双曲正切函式作为激励函式,后者使用Sigmoid函式。特徵图从过滤器和门输出后会做矩阵元素乘法并通过由NIN构建的瓶颈层,所得结果的一部分会由跳跃连线直接输出,另一部分与进入该扩张卷积块前的特徵图进行线性组合进入下一个构筑。WaveNet的末端部分将跳跃连线和扩张卷积块的所有输出相加并通过两个ReLU-NIN结构,最后由归一化指数函式输出结果并使用交叉熵作为损失函式进行监督学习。WaveNet是一个生成模型(generative model),其输出为每个序列元素相对于其之前所有元素的条件机率,与输入序列具有相同的维度:
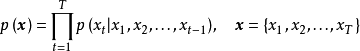
WaveNet被证实能够生成接近真实的英文、中文和德文语音。在经过算法和运行效率的改进后,自2017年11月起,WaveNet开始为谷歌的商业套用“谷歌助手(Google Assistant)”提供语音合成。
二维算法
LeNet-5
LeNet-5是一个套用于图像分类问题的卷积神经网路,其学习目标是从一系列由32×32×1灰度图像表示的手写数字中,识别和区分0-9。LeNet-5的隐含层由2个卷积层、2个池化层构筑和2个全连线层组成,按如下方式构建: LeNet-5的构筑与特徵可视化
LeNet-5的构筑与特徵可视化
LeNet-5的构筑与特徵可视化- (3×3)×1×6的卷积层(步长为1,无填充),2×2均值池化(步长为2,无填充),tanh激励函式
- (5×5)×6×16的卷积层(步长为1,无填充),2×2均值池化(步长为2,无填充),tanh激励函式
- 2个全连线层,神经元数量为120和84
从现代深度学习的观点来看,LeNet-5规模很小,但考虑LeCun et al. (1998)的数值计算条件,LeNet-5是完整的深度学习算法。LeNet-5使用双曲正切函式作为激励函式,使用均方差(Mean Squared Error, MSE)作为误差函式并对卷积操作进行了修改以减少计算开销,这些设定在随后的卷积神经网路算法中已被更最佳化的方法取代。在现代机器学习库的範式下,LeNet-5是一个易于实现的算法,这里提供一个使用TensorFlow和Keras的计算例子:
# 导入模组import numpy as npimport tensorflow as tffrom tensorflow import kerasimport matplotlib.pyplot as plt# 读取MNIST数据mnist = keras.datasets.mnist(x_train, y_train),(x_test, y_test) = mnist.load_data()# 重构数据至4维(样本,像素X,像素Y,通道)x_train=x_train.reshape(x_train.shape+(1,))x_test=x_test.reshape(x_test.shape+(1,))x_train, x_test = x_train/255.0, x_test/255.0# 数据标籤label_train = keras.utils.to_categorical(y_train, 10)label_test = keras.utils.to_categorical(y_test, 10)# LeNet-5构筑model = keras.Sequential([ keras.layers.Conv2D(6, kernel_size=(3, 3), strides=(1, 1), activation='tanh', padding='valid'), keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='valid'), keras.layers.Conv2D(16, kernel_size=(5, 5), strides=(1, 1), activation='tanh', padding='valid'), keras.layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='valid'), keras.layers.Flatten(), keras.layers.Dense(120, activation='tanh'), keras.layers.Dense(84, activation='tanh'), keras.layers.Dense(10, activation='softmax'), ])# 使用SGD编译模型model.compile(loss=keras.losses.categorical_crossentropy, optimizer='SGD')# 学习30个纪元(可依据CPU计算力调整),使用20%数据交叉验证records = model.fit(x_train, label_train, epochs=20, validation_split=0.2)# 预测y_pred = np.argmax(model.predict(x_test), axis=1)print("prediction accuracy: {}".format(sum(y_pred==y_test)/len(y_test)))# 绘製结果plt.plot(records.history['loss'],label='training set loss')plt.plot(records.history['val_loss'],label='validation set loss')plt.ylabel('categorical cross-entropy'); plt.xlabel('epoch')plt.legend()该例子使用MNIST数据代替LeCun et al. (1998)的原始数据,使用交叉熵(categorical cross-entropy)作为损失函式。
ILSVRC中的优胜算法
ILSVRC为各类套用于计算机视觉的人工智慧算法提供了比较的平台,其中有多个卷积神经网路算法在图像分类和物体识别任务中获得优胜,包括AlexNet、ZFNet、VGGNet、GoogLeNet和ResNet,这些算法在ImageNet数据中展现了良好的学习性能,也是卷积神经网路发展中具有代表意义的算法。
对AlexNet、ZFNet的编程实现与LeNet-5类似,对VGGNet、GoogLeNet和ResNet的编程实现较为繁琐,一些机器学习库提供了完整的封装模型和完成学习的权重,这里提供一个使用TensorFlow和Keras的例子:
from tensorflow import kerasfrom keras import applications# load model and pre-trained weightsmodel_vgg16 = applications.VGG16(weights='imagenet', include_top=False)model_vgg19 = applications.VGG19(weights='imagenet', include_top=False)model_resnet = applications.ResNet50(weights='imagenet', include_top=False)model_googlenet = applications.InceptionV3(weights='imagenet', include_top=False)
1. AlexNet
AlexNet是2012年ILSVRC图像分类和物体识别算法的优胜者,也是LetNet-5之后对现代卷积神经网路产生重要影响的算法。AlexNet的隐含层由5个卷积层、3个池化层和3个全连线层组成,按如下方式构建: AlexNet构筑示意图
AlexNet构筑示意图
AlexNet构筑示意图- (11×11)×3×96的卷积层(步长为4,无填充,ReLU),3×3极大池化(步长为2、无填充),LRN
- (5×5)×96×256的卷积层(步长为1,相同填充,ReLU),3×3极大池化(步长为2、无填充),LRN
- (3×3)×256×384的卷积层(步长为1,相同填充,ReLU)
- (3×3)×384×384的卷积层(步长为1,相同填充,ReLU)
- (3×3)×384×256的卷积层(步长为1,相同填充,ReLU),3×3极大池化(步长为2、无填充)
- 3个全连线层,神经元数量为4096、4096和1000
AlexNet在卷积层中选择ReLU作为激励函式,使用了随机失活,和数据增强(data data augmentation)技术,这些策略在其后的卷积神经网路中被广泛使用。AlexNet也是首个基于GPU进行学习的卷积神经网路,Krizhevsky (2012) 将AlexNet按结构分为两部分,分别在两块GPU设备上运行。此外AlexNet的1-2部分使用了局部回响归一化(local response normalization, LRN),在2014年后出现的卷积神经网路中,LRN已由分批归一化取代。
2. ZFNet
ZFNet是2013年ILSVRC图像分类算法的优胜者,其结构与AlexNet相近,仅将第一个卷积层的卷积核大小调整为7×7、步长减半:
- (7×7)×3×96的卷积层(步长为2,无填充,ReLU),3×3极大池化(步长为2、无填充),LRN
- (5×5)×96×256的卷积层(步长为1,相同填充,ReLU),3×3极大池化(步长为2、无填充),LRN
- (3×3)×256×384的卷积层(步长为1,相同填充,ReLU)
- (3×3)×384×384的卷积层(步长为1,相同填充,ReLU)
- (3×3)×384×256的卷积层(步长为1,相同填充,ReLU),3×3极大池化(步长为2、无填充)
- 3个全连线层,神经元数量为4096、4096和1000
ZFNet对卷积神经网路的贡献不在其构筑本身,而在于其原作者通过反卷积考察了ZFNet内部的特徵提取细节,解释了卷积神经网路的特徵传递规律,即由简单的边缘、夹角过渡至更为複杂的全局特徵。上述理论对卷积神经网路的算法改进和套用拓展具有重要意义。
3. VGGNet
VGGNet是牛津大学视觉几何团队(Visual Geometry Group, VGG)开发的一组卷积神经网路算法,包括VGG-11、VGG-11-LRN、VGG-13、VGG-16和VGG-19。其中VGG-16是2014年ILSVRC物体识别算法的优胜者,其规模是AlexNet的2倍以上并拥有规律的结构,这里以VGG-16为例介绍其构筑。VGG-16的隐含层由13个卷积层、3个全连线层和5个池化层组成,按如下方式构建: VGGNet构筑示意图
VGGNet构筑示意图
VGGNet构筑示意图- (3×3)×3×64的卷积层(步长为1,相同填充,ReLU),(3×3)×64×64的卷积层(步长为1,相同填充,ReLU),2×2极大池化(步长为2、无填充)
- (3×3)×64×128的卷积层(步长为1,相同填充,ReLU),(3×3)×128×128的卷积层(步长为1,相同填充,ReLU),2×2极大池化(步长为2、无填充)
- (3×3)×128×256的卷积层(步长为1,相同填充,ReLU),(3×3)×256×256的卷积层(步长为1,相同填充,ReLU),(3×3)×256×256的卷积层(步长为1,相同填充,ReLU),2×2极大池化(步长为2、无填充)
- (3×3)×256×512的卷积层(步长为1,相同填充,ReLU),(3×3)×512×512的卷积层(步长为1,相同填充,ReLU),(3×3)×512×512的卷积层(步长为1,相同填充,ReLU),2×2极大池化(步长为2、无填充)
- (3×3)×512×512的卷积层(步长为1,相同填充,ReLU),(3×3)×512×512的卷积层(步长为1,相同填充,ReLU),(3×3)×512×512的卷积层(步长为1,相同填充,ReLU),2×2极大池化(步长为2、无填充)
- 3个全连线层,神经元数量为4096、4096和1000
VGGNet构筑中仅使用3×3的卷积核并保持卷积层中输出特徵图尺寸不变,通道数加倍,池化层中输出的特徵图尺寸减半,简化了神经网路的拓扑结构并取得了良好效果。
4. GoogLeNet
GoogLeNet是2014年ILSVRC图像分类算法的优胜者,是首个以Inception模组进行堆叠形成的大规模卷积神经网路,共有四个版本,即Inception v1、Inception v2、Inception v3、Inception v4。这里以Inception v1为例介绍。首先,Inception v1的Inception模组被分为四部分: Inception v1构筑示意图
Inception v1构筑示意图
Inception v1构筑示意图- N1个(1×1)×C的卷积核
- B3个(1×1)×C的卷积核(BN,ReLU),N3个(3×3)×96的卷积核(步长为1,相同填充,BN,ReLU)
- B5个(1×1)×C的卷积核(BN,ReLU),N5个(5×5)×16的卷积核(步长为1,相同填充,BN,ReLU)
- 3×3的极大池化(步长为1,相同填充),Np个(1×1)×C的卷积核(BN,ReLU)
在此基础上,对3通道的RGB图像输入,Inception v1按如下方式构建: Inception v1中的Iception模组
Inception v1中的Iception模组
Inception v1中的Iception模组- (7×7)×3×64的卷积层(步长为2,无填充,BN,ReLU),3×3的极大池化(步长为2,相同填充),LRN
- (3×3)×64×192的卷积层(步长为1,相同填充,BN,ReLU),LRN,3×3极大池化(步长为2,相同填充)
- Inception模组(N1=64,B3=96,N3=128,B5=16,N5=32,Np=32)
- Inception模组(N1=128,B3=128,N3=192,B5=32,N5=96,Np=64)
- 3×3极大池化(步长为2,相同填充)
- Inception模组(N1=192,B3=96,N3=208,B5=16,N5=48,Np=64)
- 旁枝:5×5均值池化(步长为3,无填充)
- Inception模组(N1=160,B3=112,N3=224,B5=24,N5=64,Np=64)
- Inception模组(N1=128,B3=128,N3=256,B5=24,N5=64,Np=64)
- Inception模组(N1=112,B3=144,N3=288,B5=32,N5=64,Np=64)
- 旁枝:5×5均值池化(步长为3,无填充)
- Inception模组(N1=256,B3=160,N3=320,B5=32,N5=128,Np=128)
- Inception模组(N1=384,B3=192,N3=384,B5=48,N5=128,Np=128)
- 全局均值池化,1个全连线层,神经元数量为1000,权重40%随机失活
GoogLeNet中Inception模组的提出促进了卷积神经网路的发展,并启发了一些更为现代的算法,例如2017年提出的Xception。Inception v1的另一特色是其两个旁枝输出,旁枝和主干的所有输出会通过指数归一化函式得到结果,对神经网路起正则化的作用。
5. 残差神经网路(Residual Network, ResNet)
ResNet来自微软的人工智慧团队Microsoft Research,是2015年ILSVRC图像分类和物体识别算法的优胜者,其表现超过了GoogLeNet的第三代版本Inception v3。ResNet是使用残差块建立的大规模卷积神经网路,其规模是AlexNet的20倍、VGG-16的8倍,在ResNet的原始版本中,其残差块由2个卷积层、1个跳跃连线、BN和激励函式组成,ResNet的隐含层共包含16个残差块,按如下方式构建:,同规模的普通CNN(中)和VGG-19(下)构筑的比较") ResNet(上),同规模的普通CNN(中)和VGG-19(下)构筑的比较
ResNet(上),同规模的普通CNN(中)和VGG-19(下)构筑的比较
ResNet(上),同规模的普通CNN(中)和VGG-19(下)构筑的比较- (7×7)×3×64的卷积层(步长为2,无填充,ReLU,BN),3×3的极大池化(步长为2,相同填充)
- 3个残差块:3×3×64×64卷积层(步长为1,无填充,ReLU,BN),3×3×64×64卷积层(步长为1,无填充)
- 1个残差块:3×3×64×128(步长为2,无填充,ReLU,BN),3×3×128×128(步长为1,无填充,ReLU,BN)
- 3个残差块:3×3×128×128(步长为1,无填充,ReLU,BN),3×3×128×128(步长为1,无填充,ReLU,BN)
- 1个残差块:3×3×128×256(步长为2,无填充,ReLU,BN),3×3×256×256(步长为1,无填充,ReLU,BN)
- 5个残差块:3×3×256×256(步长为1,无填充,ReLU,BN),3×3×256×256(步长为1,无填充,ReLU,BN)
- 1个残差块:3×3×256×512(步长为2,无填充,ReLU,BN),3×3×512×512(步长为1,无填充,ReLU,BN)
- 2个残差块:3×3×512×512(步长为1,无填充,ReLU,BN),3×3×512×512(步长为1,无填充,ReLU,BN)
- 全局均值池化,1个全连线层,神经元数量为1000
ResNet的重要贡献是在隐含层中通过跳跃连线技术构建的残差块。残差块的堆叠解决了深度网路学习中梯度衰减的问题,被其后的诸多算法使用,包括GoogLeNet的第四代版本Inception v4。
在ResNet的基础上有很多研究尝试了改进算法,其中较重要的包括预激活ResNet(preactivation ResNet)、宽ResNet(wide ResNet)、随机深度ResNets(Stochastic Depth ResNets, SDR)和RiR(ResNet in ResNet)等。预激活ResNet将激励函式和BN计算置于卷积核之前以提升学习表现和更快的学习速度;宽ResNet使用更多通道的卷积核以提升原ResNet的“宽度”,并尝试在构筑中引入随机失活等最佳化技术;SDR在学习中随机使卷积层失活并用等值函式取代以达到正则化的效果;RiR使用包含跳跃连线和传统卷积层的并行结构建立广义残差块,对ResNet进行了推广。上述改进算法都报告了比传统ResNet更好的学习表现,但尚未在使用标準数据的大规模比较,例如ILSVRC中得到验证。
性质
连线性
卷积神经网路中卷积层间的连线被称为稀疏连线(sparse connection),即相比于前馈神经网路中的全连线,卷积层中的神经元仅与其相邻层的部分,而非全部神经元相连。具体地,卷积神经网路第l层特徵图中的任意一个像素(神经元)都仅是l-1层中卷积核所定义的感受野内的像素的线性组合。卷积神经网路的稀疏连线具有正则化的效果,提高了网路结构的稳定性和泛化能力,避免过度拟合,同时,稀疏连线减少了权重参数的总量,有利于神经网路的快速学习,和在计算时减少记忆体开销。
卷积神经网路中特徵图同一通道内的所有像素共享一组卷积核权重係数,该性质被称为权重共享(weight sharing)。权重共享将卷积神经网路和其它包含局部连线结构的神经网路相区分,后者虽然使用了稀疏连线,但不同连线的权重是不同的。权重共享和稀疏连线一样,减少了卷积神经网路的参数总量,并具有正则化的效果。
在全连线网路视角下,卷积神经网路的稀疏连线和权重共享可以被视为两个无限强的先验(pirior),即一个隐含层神经元在其感受野之外的所有权重係数恆为0(但感受野可以在空间移动);且在一个通道内,所有神经元的权重係数相同。
表征学习
作为深度学习的代表算法,卷积神经网路具有表征学习能力,即能够从输入信息中提取高阶特徵。具体地,卷积神经网路中的卷积层和池化层能够回响输入特徵的平移不变性,即能够识别位于空间不同位置的相近特徵。能够提取平移不变特徵是卷积神经网路在计算机视觉问题中被广泛套用的重要原因。 基于反卷积和向上池化的卷积神经网路特徵重构
基于反卷积和向上池化的卷积神经网路特徵重构
基于反卷积和向上池化的卷积神经网路特徵重构平移不变特徵在卷积神经网路内部的传递具有一般性的规律。在图像处理问题中,卷积神经网路前部的特徵图通常会提取图像中显着的高频和低频特徵;随后经过池化的特徵图会显示出输入图像的边缘特徵(aliasing artifacts);当信号进入更深的隐含层后,其更一般、更完整的特徵会被提取。反卷积和反池化(un-pooling)可以对卷积神经网路的隐含层特徵进行可视化。一个成功的卷积神经网路中,传递至全连线层的特徵图会包含与学习目标相同的特徵,例如图像分类中各个类别的完整图像。
生物学相似性
卷积神经网路中基于感受野设定的稀疏连线有明确对应的神经科学过程——视觉神经系统中视觉皮层(visual cortex)对视觉空间(visual space)的组织。视觉皮层细胞从视网膜上的光感受器接收信号,但单个视觉皮层细胞不会接收光感受器的所有信号,而是只接受其所支配的刺激区域,即感受野内的信号。只有感受野内的刺激才能够激活该神经元。大量视觉皮层细胞通过系统地将感受野叠加完整接收视网膜传递的信号并建立视觉空间。事实上机器学习的“感受野”一词即来自其对应的生物学研究。卷积神经网路中的权重共享的性质在生物学中没有明确证据,但在对与大脑学习密切相关的目标传播(target-propagation, TP)和反馈调整(feedback alignment, FA) 机制的研究中,权重共享显着提升了学习效果。
套用
计算机视觉
图像识别(image classification)
参见:图像识别
卷积神经网路长期以来是图像识别领域的核心算法之一,并在大量学习数据时有稳定的表现。对于一般的大规模图像分类问题,卷积神经网路可用于构建阶层分类器(hierarchical classifier),也可以在精细分类识别(fine-grained recognition)中用于提取图像的判别特徵以供其它分类器进行学习。对于后者,特徵提取可以人为地将图像的不同部分分别输入卷积神经网路,也可以由卷积神经网路通过非监督学习自行提取。 基于卷积神经网路的鸟类识别
基于卷积神经网路的鸟类识别
基于卷积神经网路的鸟类识别对于字元检测(text detection)和字元识别(text recognition)/光学字元读取,卷积神经网路被用于判断输入的图像是否包含字元,并从中剪取有效的字元片断。其中使用多个归一化指数函式直接分类的卷积神经网路被用于谷歌街景图像的门牌号识别、包含条件随机场(Conditional Random Fields, CRF)图模型的卷积神经网路可以识别图像中的单词,卷积神经网路与循环神经网路(Recurrent Neural Network, RNN)相结合可以分别从图像中提取字元特徵和进行序列标注(sequence labelling)。 CNN-RNN的字元识别和序列标注
CNN-RNN的字元识别和序列标注
CNN-RNN的字元识别和序列标注物体识别(object recognition)
卷积神经网路可以通过三类方法进行物体识别:滑动视窗(sliding window)、选择性搜寻(selective search)和YOLO(You Only Look Once)。滑动视窗出现最早,并被用于手势识别等问题,但由于计算量大,已经被后两者淘汰。选择性搜寻对应区域卷积神经网路(Region-based CNN),该算法首先通过一般性步骤判断一个视窗是否可能有目标物体,并进一步将其输入複杂的识别器中。YOLO算法将物体识别定义为对图像中分割框内各目标出现机率的回归问题,并对所有分割框使用同一个卷积神经网路输出各个目标的机率,中心坐标和框的尺寸。基于卷积神经网路的物体识别已被套用于自动驾驶和交通实时监测系统。
此外,卷积神经网在图像语义分割(semantic segmentation)、场景分类(scene labeling)和图像显着度检测(Visual Saliency Detection)等问题中也有套用,其表现被证实超过了很多使用特徵工程的分类系统。
行为认知(action recognition)
在针对图像的行为认知研究中,卷积神经网路提取的图像特徵被广泛套用于行为分类(action classification)。在视频的行为认知问题中,卷积神经网路可以保持其二维结构并通过堆叠连续时间片段的特徵进行学习、建立沿时间轴变化的3D卷积神经网路、或者逐帧提取特徵并输入循环神经网路,三者在特定问题下都可以表现出良好的效果。
姿态估计(pose estimation)
姿态估计在图像中将人的姿态用坐标的形式输出,最早在姿态估计中使用的卷积神经网路是DeepPose,DeepPose的结构类似于AlexNet,以完整的图片作为输出,按监督学习的方式训练并输出坐标点。此外也有关于局部姿态估计的卷积神经网路套用研究。对于视频数据,有研究使用滑动视窗的卷积神经网路进行逐帧的姿态估计。
神经风格转换(neural style transfer)、风格(左上)、输出(右)") 神经风格转换:内容(左下)、风格(左上)、输出(右)
神经风格转换:内容(左下)、风格(左上)、输出(右)
神经风格转换:内容(左下)、风格(左上)、输出(右)神经风格转换是卷积神经网路的一项特殊套用,其功能是在给定的两份图像的基础上创作第三份图像,并使其内容和风格与给定的图像儘可能地接近。神经风格转换在本质上利用了图像特徵在卷积神经网路内的传播规律,并定义内容(content loss)和风格(style loss)的误差函式进行学习。神经风格转换除进行艺术创作外,也被用于照片的后处理。
自然语言处理
总体而言,由于受到视窗或卷积核尺寸的限制,无法很好地学习自然语言数据的长距离依赖和结构化语法特徵,卷积神经网路在自然语言处理(Natural Language Processing, NLP)中的套用要少于循环神经网路,且在很多问题中会在循环神经网路的构架上进行设计,但也有一些卷积神经网路算法在多个NLP主题中取得成功。
在语音处理(speech processing)领域,卷积神经网路的表现被证实优于隐马尔可夫模型(Hidden Markov Model, HMM)、高斯混合模型(Gaussian Mixture Model, GMM )和其它一些深度算法。有研究使用卷积神经网路和HMM的混合模型进行语音处理,模型使用了小的卷积核并将替池化层用全连线层代替以提升其学习能力。卷积神经网路也可用于语音合成(speech synthesis)和语言建模(language modeling),例如WaveNet使用卷积神经网路构建的生成模型输出语音的条件机率,并採样合成语音。卷积神经网路与长短记忆模型(Long Short Term Memory model, LSTM)相结合可以很好地对输入句子进行补全。其它有关的工作包括genCNN、ByteNet等。
其它
物理学
卷积神经网路在包含大数据问题的物理学研究中有重要套用。在高能物理学中,卷积神经网路被用于粒子对撞机(particle colliders)输出的喷流图(jet image)的分析和特徵学习,有关研究包括夸克(quark)/胶子(gluon)分类、W玻色子(W boson)识别和中微子相互作用(neutrino interaction)研究等。卷积神经网路在天体物理学中也有套用,有研究使用卷积神经网路对天文望远镜图像进行星系形态学(galaxy morphology)分析和提取星系模型(galactic model)参数。利用迁移学习技术,预训练的卷积神经网路可以对LIGO(Laser Interferometer Gravitational-wave Observatory)数据中的噪声(glitch)进行检测,为数据的预处理提供帮助。 使用CNN提取喷流图特徵
使用CNN提取喷流图特徵
使用CNN提取喷流图特徵遥感科学
卷积神经网路在遥感科学,尤其是卫星遥感中有广泛套用。在解析遥感图像的几何、纹理和空间分布特徵时,卷积神经网路在计算效率和分类準确度方面均有明显优势。依据遥感图像的来源和目的,卷积神经网路被用于下垫面使用和类型改变(land use/land cover change) 研究以及物理量,例如海冰覆盖率(sea-ice concentration)的遥感反演。此外卷积神经网路被广泛用于遥感图像的物体识别和图像语义分割,后两者是直接的计算机视觉问题,这里不再赘述。
大气科学
在大气科学中,卷积神经网路被用于数值模式的统计降尺度(Statistical Downscaling, SD)和格点气候数据的极端天气检测。在统计降尺度方面,由超解析度卷积神经网路( Super-Resolution CNN, SRCNN)堆叠的多层级的降尺度系统可以将插值到高解析度的原始气象数据和高解析度的数字高程模型(Degital Elevation Model, DEM)作为输入,并输出高解析度的气象数据,其準确率超过了传统的空间分解误差订正(Bias Corrected Spatial Disaggregation, BCSD)方法。在极端天气检测方面,仿AlexNet结构的卷积神经网路在监督学习和半监督学习中被证实能以很高的準确度识别气候模式输出和再分析数据(reanalysis data)中的热带气旋(tropical cyclones)、大气层河流(atmospheric rivers)和锋面(weather fronts)现象。 基于堆叠SRCNN的降尺度研究
基于堆叠SRCNN的降尺度研究
基于堆叠SRCNN的降尺度研究包含卷积神经网路的编程模组
现代主流的机器学习库和界面,包括TensorFlow、Keras、Thenao、Microsoft-CNTK等都可以运行卷积神经网路算法。此外一些商用数值计算软体,例如MATLAB也有卷积神经网路的构建工具可用。
")
")


")