
匈牙利算法是一种在多项式时间内求解任务分配问题的组合最佳化算法,并推动了后来的原始对偶方法。美国数学家哈罗德·库恩于1955年提出该算法。此算法之所以被称作匈牙利算法,是因为算法很大一部分是基于以前匈牙利数学家Dénes Kőnig和Jenő Egerváry的工作之上创建起来的。
基本介绍
- 中文名:匈牙利算法
- 外文名:Hungary
- 提出者:Edmonds
- 提出时间:1965
- 算法的核心:寻找增广路径
简介
设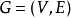 是一个无向图。如顶点集V可分割为两个互不相交的子集
是一个无向图。如顶点集V可分割为两个互不相交的子集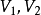 ,选择这样的子集中边数最大的子集称为图的最大匹配问题(maximal matching problem)。
,选择这样的子集中边数最大的子集称为图的最大匹配问题(maximal matching problem)。
如果一个匹配中,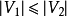 且匹配数
且匹配数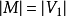 ,则称此匹配为完全匹配,也称作完备匹配。特别的当
,则称此匹配为完全匹配,也称作完备匹配。特别的当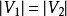 称为完美匹配。
称为完美匹配。
概念
在介绍匈牙利算法之前还是先提一下几个概念,下面M是G的一个匹配。
若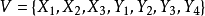 ,
,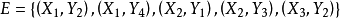 ,其中边
,其中边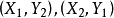 已经在匹配M上。
已经在匹配M上。
M-交错路:p是G的一条通路,如果p中的边为属于M中的边与不属于M但属于G中的边交替出现,则称p是一条M-交错路。如:路径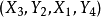 ,
,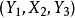 。
。
M-饱和点:对于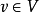 ,如果v与M中的某条边关联,则称v是M-饱和点,否则称v是非M-饱和点。如
,如果v与M中的某条边关联,则称v是M-饱和点,否则称v是非M-饱和点。如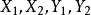 都属于M-饱和点,而其它点都属于非M-饱和点。
都属于M-饱和点,而其它点都属于非M-饱和点。
M-可增广路:p是一条M-交错路,如果p的起点和终点都是非M-饱和点,则称p为M-可增广路。如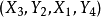 (不要和流网路中的增广路径弄混了)。
(不要和流网路中的增广路径弄混了)。
求最大匹配的一种显而易见的算法是:先找出全部匹配,然后保留匹配数最多的。但是这个算法的时间複杂度为边数的指数级函式。因此,需要寻求一种更加高效的算法。下面介绍用增广路求最大匹配的方法(称作匈牙利算法,匈牙利数学家Edmonds于1965年提出)。
增广路的定义(也称增广轨或交错轨):
若P是图G中一条连通两个未匹配顶点的路径,并且属于M的边和不属于M的边(即已匹配和待匹配的边)在P上交替出现,则称P为相对于M的一条增广路径。
由增广路的定义可以推出下述三个结论:
(1)P的路径个数必定为奇数,第一条边和最后一条边都不属于M。
(2)将M和P进行取反操作可以得到一个更大的匹配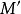 。
。
(3)M为G的最大匹配若且唯若不存在M的增广路径。
算法轮廓:
(1)置M为空
(2)找出一条增广路径P,通过异或操作获得更大的匹配 代替M
(3)重複(2)操作直到找不出增广路径为止
複杂度
时间複杂度邻接矩阵:最坏为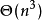 邻接表:
邻接表: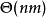
空间複杂度 邻接矩阵: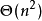 邻接表:
邻接表: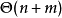
样例程式
格式说明
输入格式:
第1行3个整数, 的节点数目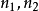 ,G的边数m
,G的边数m
第2-m+1行,每行两个整数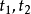 ,代表
,代表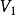 中编号为
中编号为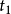 的点和
的点和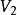 中编号为
中编号为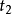 的点之间有边相连
的点之间有边相连
输出格式:
1个整数ans,代表最大匹配数
邻接矩阵-C
#include<stdio.h>#include<string.h>int n1, n2, m, ans;int result[101];//记录V2中的点匹配的点的编号bool state[101];//记录V2中的每个点是否被搜寻过bool data[101][101];//邻接矩阵true代表有边相连void init(){ int t1, t2; memset(data, 0, sizeof(data)); memset(result, 0, sizeof(result)); ans = 0; scanf("%d%d%d", &n1, &n2, &m); for(int i = 1; i <= m; i++) { scanf("%d%d", &t1, &t2); data[t1][t2] = true; } return;}bool find(inta){ for(int i = 1; i <= n2; i++) { if(data[a][i] == 1 && !state[i]) //如果节点i与a相邻并且未被查找过 { state[i] = true; //标记i为已查找过 if(result[i] == 0 //如果i未在前一个匹配M中 || find(result[i])) //i在匹配M中,但是从与i相邻的节点出发可以有增广路 { result[i] = a; //记录查找成功记录 return true;//返回查找成功 } } } return false;}int main(){ init(); for(int i = 1; i <= n1; i++) { memset(state, 0, sizeof(state)); //清空上次搜寻时的标记 if(find(i)) { ans++; //从节点i尝试扩展 } } printf("%d\n", ans); return 0;}邻接矩阵-pascal
Programhungary;Constmax=100;Vardata:array[1..max,1..max]ofboolean;{邻接矩阵}result:array[1..max]ofinteger;{记录当前连线方式}state:array[1..max]ofboolean;{记录是否遍历过,防止死循环}m,n1,n2,i,t1,t2,ans:integer;Function dfs(p:integer):boolean;vari:integer;beginfor i:=1 to n2 doif data[p,i]and not(state[i]) then{有边存在且没有被搜寻过}beginstate[i]:=true;if (result[i]=0)or dfs(result[i]) then{没有被连过或寻找到增广路}beginresult[i]:=p;exit(true);end;end;exit(false);end;beginreadln(n1,n2,m);fillchar(data,sizeof(data),0);fori:=1 to mdobeginreadln(t1,t2);data[t1,t2]:=true;end;fillchar(result,sizeof(result),0);ans:=0;fori:=1 to n1 dobeginfillchar(state,sizeof(state),0);if dfs(i) then inc(ans);end;writeln(ans);end.邻接表-pascal(使用动态鍊表)
(方法基于之前的邻接矩阵-pascal)
programhungarian_algorithm;//匈牙利算法typenode=^link;//鍊表定义link=recordg:longint;//指向节点next:node;end;varn1,n2,m,a,v1,v2,ans:longint;flag:array[1..1000000]ofboolean;//记录在main递归过程中是否已访问过,防止死循环nd:array[1..1000000]ofnode;//邻接表resultt:array[1..1000000]oflongint;//记录v2中节点的最终匹配于v1中的几号节点functionmain(wei:longint):boolean;varp:node;beginp:=nd[wei];whilep<>nildobeginifflag[p^.g]{没有被搜寻过}thenbeginflag[p^.g]:=false;if(resultt[p^.g]=0)or(main(resultt[p^.g])){没有被连过或原来指向的节点寻找到新的增广路}thenbeginresultt[p^.g]:=wei;exit(true);end;end;p:=p^.next;end;exit(false)end;procedureaddd(v1,v2:longint);//建立邻接表过程varp:node;beginnew(p);p^.g:=v2;p^.next:=nd[v1];nd[v1]:=p;end;beginreadln(n1,n2,m);fora:=1tomdobeginreadln(v1,v2);addd(v1,v2);end;ans:=0;fillchar(resultt,sizeof(resultt),0);fora:=1ton1dobeginfillchar(flag,sizeof(flag),true);ifmain(a)theninc(ans);end;writeln(ans);fora:=1ton2doifresultt[a]<>0thenwriteln(resultt[a],'---',a);end.邻接表-C++
#include<iostream>#include<cstring>using namespace std;//定义鍊表struct link{ int data;//存放数据 link*next;//指向下一个节点 link(int=0);};link::link(int n){ data=n; next=NULL;}int n1,n2,m,ans=0;int result[101];//记录n1中的点匹配的点的编号bool state[101];//记录n1中的每个点是否被搜寻过link*head[101];//记录n2中的点的邻接节点link*last[101];//邻接表的终止位置记录//判断能否找到从节点n开始的增广路bool find(const int n){ link*t=head[n]; while(t!=NULL){//n仍有未查找的邻接节点时 if(!(state[t->data])){//如果邻接点t->data未被查找过 state[t->data]=true;//标记t->data为已经被找过 if((result[t->data]==0)||//如果t->data不属于前一个匹配M (find(result[t->data]))){//如果t->data匹配到的节点可以寻找到增广路 result[t->data]=n;//那幺可以更新匹配M',其中n1中的点t->data匹配n return true;//返回匹配成功的标誌 } } t=t->next;//继续查找下一个n的邻接节点 } return false;}int main(){ int t1=0,t2=0; cin>>n1>>n2>>m; for(int i=0;i<m;i++){ cin>>t1>>t2; if(last[t1]==NULL) last[t1]=head[t1]=new link(t2); else last[t1]=last[t1]->next=new link(t2); } for(int i=1;i<=n1;i++){ memset(state,0,sizeof(state)); if(find(i))ans++; } cout<<ans<<endl; return 0;}邻接矩阵-C++
#include<iostream>#include<cstring>using namespace std;int map[105][105];int visit[105],flag[105];int n,m;bool dfs(int a){ for(int i=1; i<=n; i++) { if(map[a][i]&&!visit[i]) { visit[i]=1; if(flag[i]==0||dfs(flag[i])) { flag[i]=a; return true; } } } return false;}int main(){ int n1,n2; while(cin>>n1 >>n2 >>m) { n=n1; memset(map,0,sizeof(map)); for(int i=1; i<=m; i++) { int x,y; cin>>x>>y; map[x][y]=1; } memset(flag,0,sizeof(flag)); int result=0; for(int i=1; i<=n1; i++) { memset(visit,0,sizeof(visit)); if(dfs(i))result++; } cout<<result<<endl; } return 0;}")
")


")